
If you’ve been following AI developments over the past couple years, you’ve probably heard the term “RAG” thrown around—Retrieval-Augmented Generation. It’s the technology that lets AI systems pull in external knowledge instead of relying solely on what they learned during training. But there’s a newer evolution that’s starting to make waves: Graph RAG. And understanding the difference could fundamentally change how you think about building AI systems that actually know things.
Let me break this down from the ground up, because even if you’ve never heard of a graph database, you’ll want to understand why this matters.
The Problem RAG Was Built to Solve
Large Language Models like GPT-4 and Claude have a fundamental limitation: they’re frozen in time. Their knowledge comes from training data, and that training has a cutoff date. Ask them about something that happened last week, or about your company’s internal documentation, and they’ll either admit ignorance or—worse—confidently make something up.
This is what the industry calls “hallucination,” and it’s not a bug in the traditional sense. It’s a feature of how these models work. They’re pattern-completion machines. When they don’t have real information, they complete the pattern with plausible-sounding nonsense.
RAG was the first major solution to this problem. The idea is straightforward: before the AI generates a response, you first retrieve relevant information from an external knowledge base and include it in the prompt. Now the AI has actual facts to work with instead of just its training data.
How Traditional RAG Works: Vector Databases and Embeddings
To understand Graph RAG, you first need to understand what it’s improving upon. Traditional RAG—sometimes called “naive RAG” or “vector RAG”—relies on two key technologies: embeddings and vector databases.
Embeddings: Turning Words into Math
An embedding is a way of representing text (or images, or audio) as a list of numbers—a vector. Think of it like GPS coordinates, but instead of two dimensions (latitude and longitude), you have hundreds or even thousands of dimensions.
The magic is that these numbers capture meaning. When you embed the word “cat,” it ends up positioned close to “kitten” and “feline” in this high-dimensional space. “Dog” is nearby too—it’s also a pet. But “automobile” is far away in a completely different region.
This means you can search by concept rather than exact keywords. A query for “baby dog” can successfully find documents about “puppies” even if the word “baby” never appears, because the mathematical representations are close together.
Vector Databases: Making Similarity Searchable
Once you’ve converted your documents into these mathematical representations, you need somewhere to store and search them efficiently. That’s what vector databases do. Products like Pinecone, Weaviate, and Milvus (or the pgvector extension for PostgreSQL if you want to stay in familiar territory) are designed specifically for this task.
When you query a vector database, you’re essentially asking: “Find me the documents whose mathematical representations are closest to this query.” The database uses clever algorithms—most commonly something called HNSW (Hierarchical Navigable Small World graphs)—to do this quickly without checking every single document.
The Workflow
So in a traditional RAG setup:
- You break your documents into chunks (typically 100-800 words each)
- You convert each chunk into a vector embedding
- You store those embeddings in a vector database
- When a user asks a question, you convert their question into an embedding
- You find the most similar chunks in the database
- You pass those chunks to the LLM along with the question
- The LLM generates an answer using the retrieved context
This works remarkably well for simple, direct questions where the answer exists in a single document chunk. But it has serious limitations.
Where Vector RAG Breaks Down
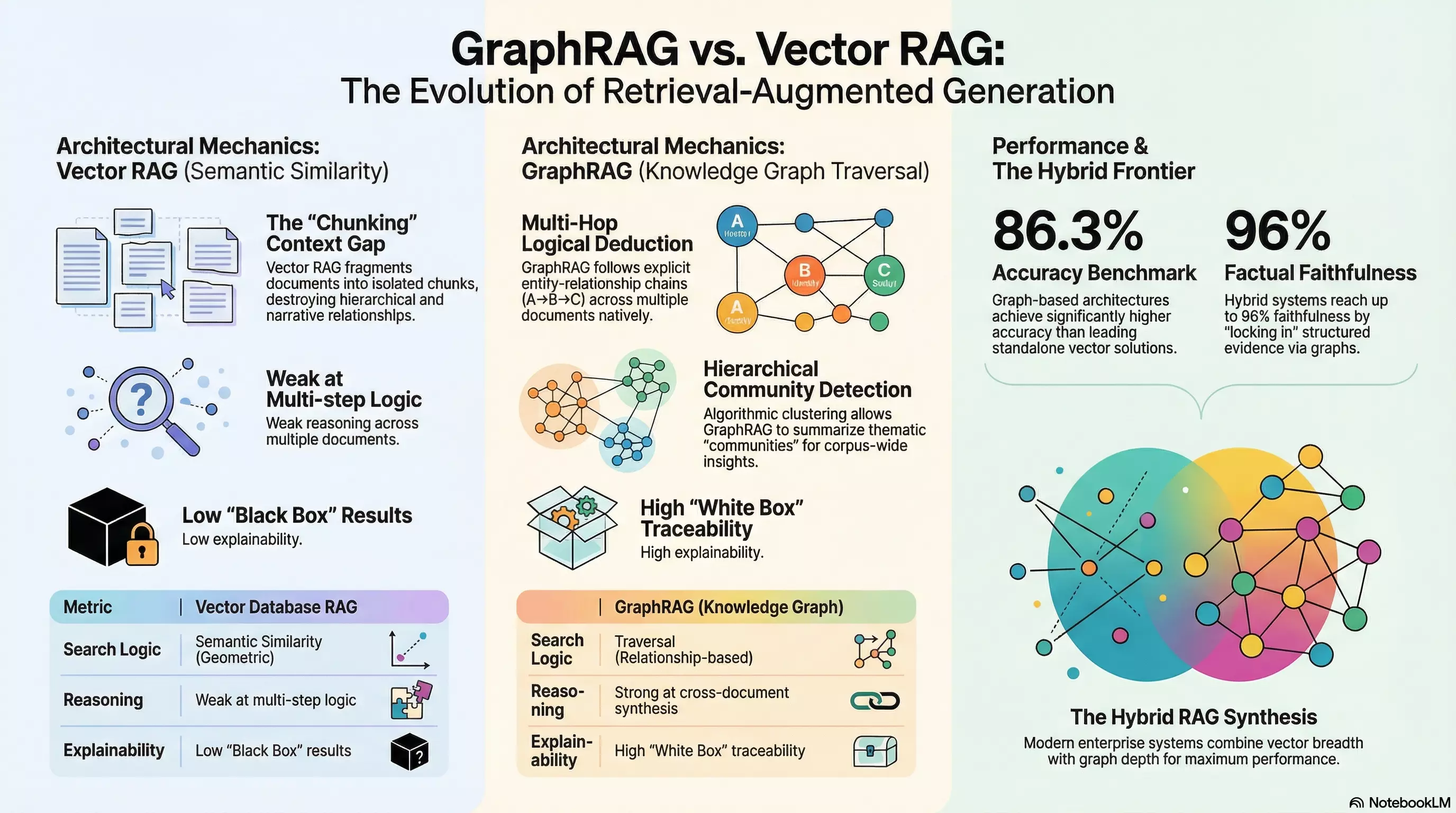
Here’s the problem: when you chop documents into isolated chunks, you destroy context. You sever the connections between related pieces of information.
Think of it like reading a book where all the pages have been shuffled. Each page might contain perfectly accurate information, but you’ve lost the narrative structure, the cause-and-effect relationships, the way one idea builds on another.
Consider a question like: “Who led Project Atlas when the Q4 budget was approved?”
A vector database might retrieve one chunk containing a manager’s biography and another chunk about Q4 budget figures. But it has no way to connect these facts. It can’t verify that this specific person was actually the project lead during that specific time period. The LLM is left to bridge the gap on its own—which means it might hallucinate a connection that doesn’t exist.
Vector retrieval finds things that are semantically similar to your query. But semantic similarity isn’t the same as logical relationship. Being “about the same topic” doesn’t mean information is actually connected in meaningful ways.
This is why researchers call vector RAG “weak at multi-step reasoning.” It excels at finding relevant haystack needles but struggles when you need to follow chains of logic across multiple sources.
There’s also the “black box” problem. When a vector database returns results, it tells you the similarity score—say, 0.89 out of 1.0. But it can’t explain why that score means the content is actually relevant to your specific question. This lack of explainability is a dealbreaker in regulated industries like healthcare, finance, and legal services, where you need to show your work.
Enter Graph RAG: Relationships as First-Class Citizens
Graph RAG takes a fundamentally different approach. Instead of treating documents as bags of similar-sounding text chunks, it models information as a network of entities connected by relationships.
What Is a Knowledge Graph?
If you’ve never encountered graph databases, the concept is simpler than it sounds. A graph is just a way of representing connections. You have:
- Nodes (also called vertices): These represent entities—people, places, organizations, concepts, documents
- Edges (also called relationships): These represent how entities connect—“works at,” “reports to,” “approved,” “authored,” “located in”
- Properties: Additional metadata attached to nodes and edges—dates, confidence scores, source references
So instead of storing “John Smith is the CEO of Acme Corp” as a text chunk, you store it as:
[John Smith] --IS_CEO_OF--> [Acme Corp]This seems like a small difference, but it’s transformative. Now the system knows the relationship exists. It’s not inferring similarity; it’s storing explicit facts.
How Graph RAG Works
The Graph RAG pipeline, heavily influenced by Microsoft Research’s 2024 framework, involves several sophisticated steps:
- Entity Extraction: An LLM reads through your documents and identifies all the entities—people, organizations, locations, concepts, events
- Relationship Extraction: The same (or another) LLM identifies how those entities relate to each other
- Entity Resolution: “The President,” “POTUS,” and “Joe Biden” get merged into a single node representing the same person
- Graph Construction: All these nodes and edges get written to a graph database like Neo4j or TigerGraph
- Community Detection: Algorithms identify clusters of closely related entities and generate summaries of each “community”
At query time, instead of finding similar text chunks, the system:
- Maps concepts in your question to specific nodes in the graph
- Traverses the graph, following edges to related entities
- Assembles a coherent sub-graph of connected facts
- Passes this structured context to the LLM
This is what enables true multi-hop reasoning. The system can follow explicit chains: “John Smith → IS_CEO_OF → Acme Corp → APPROVED → Q4 Budget → DURING → Project Atlas.” Each step is a verified relationship, not an inferred similarity.
The Numbers Don’t Lie
The theoretical advantages translate into measurable real-world performance.
In testing using the RobustQA framework—an open-domain question-answering benchmark spanning 50,000 queries across eight domains and over 32 million documents—graph-based hybrid architectures achieved 86.3% accuracy. Competing vector-only solutions ranged from 32.7% to 75.9%. That’s not a marginal improvement; it’s a different league.
Even more striking: research conducted jointly by NVIDIA and BlackRock on financial document Q&A found that hybrid Graph-Vector systems achieved 96% factual faithfulness on responses derived from complex, heavily regulated financial filings.
The knowledge graph functions to “lock in” high-precision, domain-structured evidence, while vector embeddings capture the nuanced contextual subtext that doesn’t fit neatly into explicit categories.
Local vs. Global: Two Search Modes
One of the clever innovations in Microsoft’s GraphRAG implementation is the distinction between “local” and “global” search modes.
Local search is entity-centric. You’re looking for specific facts about specific things. The system finds relevant entities via semantic similarity to their descriptions, then traverses to related entities, supporting text, and relevant community summaries.
Global search tackles a different problem entirely: questions that don’t have a specific answer in any single place. “What are the main themes in this document collection?” “What risks should I be aware of?” These require synthesizing information across the entire corpus.
Graph RAG handles this through pre-computed community summaries. The system has already identified clusters of related entities and generated high-level descriptions of what each cluster is about. For global questions, it aggregates across these summaries using a map-reduce approach—asking the LLM to extract relevant points from each community, then synthesizing the top findings into a coherent response.
This is something naive vector RAG fundamentally cannot do. Finding the most similar chunks to a question like “summarize the key themes” doesn’t produce useful results because no single chunk contains a summary of everything.
The Trade-Offs (Because There Are Always Trade-Offs)
Graph RAG isn’t a free lunch. The approach introduces significant complexity and cost, particularly at indexing time.
Building the knowledge graph requires extensive LLM calls for entity and relationship extraction. Microsoft explicitly warns that indexing can be expensive and recommends starting with small corpora to validate the approach before scaling up.
Query latency can also be higher, particularly for global searches that require aggregating across many community summaries. Each of those aggregations involves LLM calls, which add up.
There’s also the complexity of graph construction itself. Vector RAG is nearly plug-and-play: chunk your documents, call an embedding API, load into a vector database. Graph RAG requires designing an ontology, tuning extraction prompts, running community detection algorithms, and maintaining graph infrastructure.
The sweet spot, according to correlation studies, appears to be datasets containing between 1 and 3 million tokens. Within this range, entity and relationship density remains meaningful without overwhelming the system with noise. At massive scale (10+ million tokens), performance gains can plateau as graph traversals become entangled in irrelevant cross-references.
The Hybrid Future
The most sophisticated production systems don’t treat this as an either/or choice. They use both.
Hybrid RAG architectures combine vector search for rapid semantic “entry points” with graph traversal for relationship-aware context expansion. The vector engine handles variations in phrasing and fuzzy matching. The knowledge graph provides structured relationships, constraints, and provenance.
Some modern graph databases—including Neo4j and TigerGraph—now support storing vector embeddings directly on graph nodes. This allows you to execute queries like: “Find entities semantically similar to my question, then traverse their relationships to gather supporting evidence.” All in one system.
When Should You Care About Graph RAG?
Graph RAG makes the most sense when:
-
Your domain has naturally linked artifacts: Legal cases cite precedents. Software components depend on libraries. Research papers reference other papers. If relationships are first-class citizens in your domain, Graph RAG can model them properly.
-
Users ask multi-hop questions: “What vulnerabilities affect systems maintained by teams that report to the CISO?” requires following chains of relationships, not just finding similar text.
-
You need explainability: In regulated industries, being able to show why the AI reached a conclusion—with traceable paths through verified relationships—isn’t optional.
-
You need corpus-level synthesis: Questions like “What are the emerging themes?” or “How has sentiment changed over time?” require aggregation that vector RAG can’t provide.
If your use case is primarily “needle in a haystack” factoid retrieval—simple questions with answers contained in single passages—traditional vector RAG remains a strong, simpler choice.
The Bottom Line
Graph RAG represents a fundamental shift in how we think about AI knowledge systems. Instead of treating documents as bags of semantically similar chunks, we’re building actual knowledge structures—entities, relationships, hierarchies—that mirror how information actually connects in the real world.
The technology is maturing rapidly. Microsoft’s open-source GraphRAG framework, combined with increasingly capable graph databases and orchestration tools, means this isn’t just research anymore. It’s production-ready infrastructure for organizations willing to invest in the complexity.
The question isn’t whether Graph RAG will become the standard for enterprise AI. The question is how quickly your organization will need to adopt it to remain competitive. When your competitors’ AI systems can reason across relationships while yours is still pattern-matching text similarity, the gap becomes obvious fast.
Start small. Validate the approach on a bounded corpus. Measure the improvement. Then scale. The future of AI retrieval isn’t about finding similar text—it’s about understanding connected knowledge.