
Few-shot prompting has become one of the most powerful techniques in the modern AI toolkit—but it’s also one of the most misunderstood. The ability to teach a language model a new task by showing it just a handful of examples sounds almost magical, and in a sense, it is. But like any tool, knowing when to use it matters just as much as knowing how.
In this deep dive, we’ll explore the mechanics behind few-shot prompting, examine the research on when it actually improves results, and confront a surprising twist: the rise of reasoning models is fundamentally changing when examples help versus when they hurt. By the end, you’ll have a strategic framework for deciding whether your next prompt needs examples—or whether zero-shot is actually the better play.
What Is Few-Shot Prompting, Really?
At its core, few-shot prompting is a form of in-context learning (ICL)—the model’s ability to take a context composed of instructions and examples and directly generate output without any additional training. Unlike traditional machine learning, where you’d need thousands of labeled examples and expensive GPU time to fine-tune a model, few-shot prompting works entirely at inference time. The model’s weights never change.
Here’s the basic structure:
Input: What is the capital of France?
Output: Paris
Input: What is the capital of Japan?
Output: Tokyo
Input: What is the capital of Brazil?
Output:The model sees the pattern in your examples and continues it. Simple enough on the surface—but the underlying mechanics are fascinating.
The Match-and-Copy Mechanism: How Models Actually Learn In-Context
The ability to learn from examples emerges from specialized attention patterns within transformer architectures called induction heads. These heads implement a deceptively simple algorithm: they scan backward through the sequence looking for a previous occurrence of the current token, identify what followed it, and then predict that same pattern should continue.
Think of it as sophisticated pattern matching. When you provide examples in a consistent format—input followed by output, separated by clear delimiters—induction heads recognize this structure and apply it to your final query. They’re essentially saying, “I’ve seen this pattern before in this very prompt, and here’s what should come next.”
As models scale to hundreds of billions of parameters, these induction heads evolve into more abstract function vector heads that capture not just token-level patterns but the underlying task itself. Research has shown that disrupting these specific circuits causes few-shot performance to collapse entirely, even when the rest of the model remains intact.
This explains why few-shot prompting has a scaling threshold: models below a certain size struggle to maintain coherent attention across multiple examples, leading to inconsistent formatting and logic errors. Larger models develop the specialized circuitry needed for robust in-context learning.
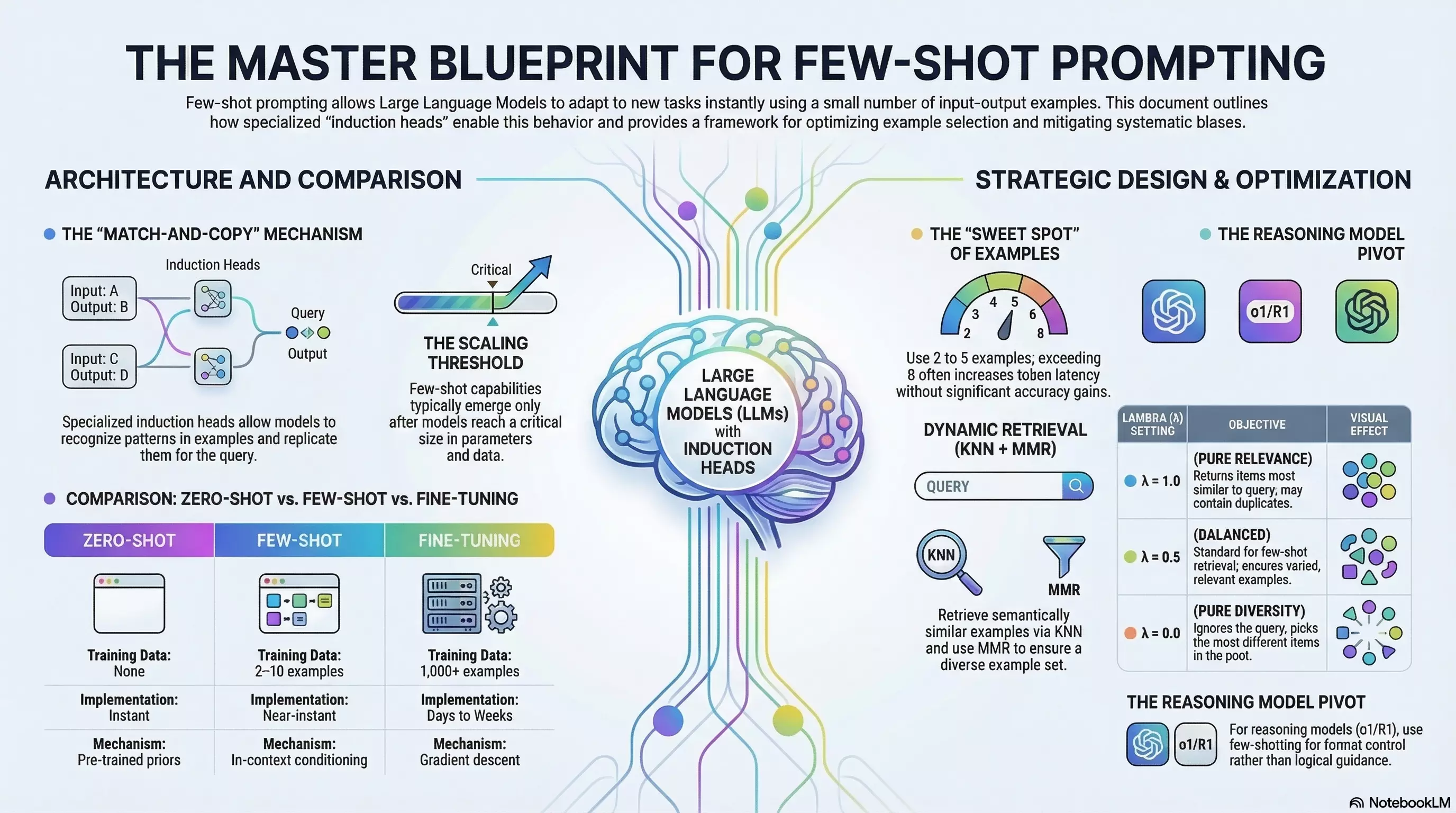
Zero-Shot vs. Few-Shot vs. Fine-Tuning: The Trade-offs
Before diving into strategy, let’s establish the playing field:
| Approach | Training Data | Cost | Flexibility | Speed |
|---|---|---|---|---|
| Zero-Shot | None | Inference only | Extremely high | Instant |
| Few-Shot | 2–10 examples | Inference (higher tokens) | High | Near-instant |
| Fine-Tuning | 1,000+ examples | High (GPU training) | Low (task-specific) | Days to weeks |
Zero-shot relies entirely on the model’s pre-trained knowledge and your instructions. Few-shot adds conditioning through examples. Fine-tuning actually modifies the model’s weights for a specific task.
The sweet spot for few-shot prompting is clear: when zero-shot isn’t quite getting the job done, but you don’t have (or don’t want to spend) the thousands of examples and compute hours required for fine-tuning.
When Few-Shot Prompting Shines
Few-shot prompting isn’t universally better than zero-shot—it’s situationally better. Here’s where the research shows clear wins:
Specialized Domains and Terminology
In clinical NLP, legal document analysis, and technical fields where precise terminology matters, few-shot examples dramatically improve accuracy. For medication attribute extraction tasks, adding just 2–3 examples boosted accuracy from 0.88 to 0.96 in benchmarks. The examples serve as anchors, preventing the model from defaulting to more generalized (but incorrect) interpretations.
Format-Critical Outputs
When your output must follow a strict, non-obvious schema—structured JSON, specific citation formats, domain-specific notation—examples are invaluable. They demonstrate not just what to produce but exactly how to format it. This is particularly true for:
- API response structures
- Database query formats
- Custom markup languages
- Compliance-specific document structures
Tool Calling and Code Generation
LangChain’s research on tool-calling performance found that dynamic few-shot retrieval significantly outperformed static prompts. When requirements vary wildly between requests, showing the model relevant examples of similar tool invocations guides it toward correct parameter usage and API patterns.
Ambiguous Tasks
When your instructions could be interpreted multiple ways, examples disambiguate. They show rather than tell, reducing the surface area for misinterpretation.
When Zero-Shot Wins (or Few-Shot Hurts)
The research reveals several scenarios where adding examples is counterproductive:
Highly Structured, Unambiguous Tasks
For standard language translation, basic sentiment analysis, or other tasks where instructions are crystal clear and the model has extensive pre-training exposure, zero-shot often matches or exceeds few-shot performance. The examples add token overhead without proportional accuracy gains.
Clinical sense disambiguation is a striking example: zero-shot prompts with expert-crafted heuristics achieved 0.88–0.96 accuracy, while adding few-shot examples actually decreased performance to 0.82 in some cases. The examples introduced noise that the precise heuristic instructions didn’t need.
Token-Constrained Environments
Every example consumes tokens. In contexts where you’re bumping against context limits or optimizing for cost, the token overhead of few-shot prompting may not justify marginal accuracy improvements. This is especially true with current pricing models where input tokens add up quickly at scale.
When Examples Introduce Bias
Few-shot prompting is highly sensitive to example selection. Systematic biases can creep in:
- Majority label bias: If 4 of your 5 examples have “positive” labels, the model may favor “positive” regardless of the actual query
- Recency bias: The model often weights the last example more heavily
- Domain label bias: Medical terminology can trigger “emergency” classifications even for neutral descriptions
If you can’t curate examples carefully, zero-shot may be more robust.
The Reasoning Model Plot Twist
Here’s where the landscape shifts dramatically. The emergence of reinforcement-learned reasoning models like OpenAI’s o1 series and DeepSeek-R1 has fundamentally changed the few-shot calculus.
These models are trained to perform extensive internal chain-of-thought reasoning before generating final answers. They already exhibit exceptional reasoning capabilities in zero-shot settings—and adding few-shot examples can actually degrade their performance.
Empirical evidence from medical and coding benchmarks shows that while few-shot prompting consistently helps GPT-4-class models, it can worsen o1-preview results. The hypothesis: examples “clutter” the model’s internal reasoning process, consume valuable reasoning tokens, or bias it toward less sophisticated reasoning paths than it would generate independently.
| Model Family | Traditional Few-Shot Effect | Reasoning Model Effect |
|---|---|---|
| GPT-4o / Claude 3.5 | Significant accuracy boost | N/A |
| OpenAI o1-preview | Potential performance drop | Use for format control only |
| DeepSeek-R1 | Minimal benefit | Alignment/formatting |
The strategic recommendation for reasoning models: default to zero-shot instructions and reserve few-shot examples purely for output format control when the schema isn’t obvious. If you must use examples, limit them to 1–2 high-quality instances to avoid overcomplicating the model’s internal search process.
Strategic Design Principles
When you do use few-shot prompting, execution matters. Here’s how to maximize effectiveness:
Use Clear Delimiters
Consistent formatting helps attention heads parse relationships between input and output. XML-like tags (<input>, <output>), triple quotation marks, or conversation turn formats (User: / Assistant:) all work well. The key is consistency—pick a delimiter style and stick with it.
The Sweet Spot: 2–5 Examples
Research consistently shows diminishing returns beyond 5–8 examples. More examples rarely improve accuracy significantly and bloat token usage and latency. For most tasks, 3–5 well-chosen examples hit the optimal trade-off.
Match Complexity
Your examples must match the complexity level of expected inputs. Overly simplistic examples cause the model to fail on nuanced queries; overly complex examples obscure the core pattern. Analyze your actual use cases and select examples that represent the realistic middle ground.
Consider Dynamic Retrieval
For production systems handling diverse queries, static example sets are often suboptimal. Dynamic retrieval—using vector embeddings and KNN search to select semantically relevant examples for each query—consistently outperforms static approaches.
To avoid redundant examples, consider Maximum Marginal Relevance (MMR), which balances query relevance against diversity in the selected set. A lambda parameter between 0.3–0.7 typically provides good results, ensuring your examples cover the task space without duplicating information.
Chain-of-Thought: Extending Few-Shot for Complex Reasoning
For multi-step reasoning tasks—complex arithmetic, symbolic logic, multi-hop inference—standard few-shot prompting often falls short. The model recognizes the pattern but fails to execute the reasoning steps correctly.
Chain-of-Thought (CoT) prompting extends few-shot by including intermediate reasoning steps in your examples:
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls.
Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans × 3 balls = 6 balls.
5 + 6 = 11 balls. The answer is 11.By demonstrating how to reason through the problem, you encourage the model to show its work. Few-shot CoT consistently outperforms zero-shot CoT (the simple “Let’s think step by step” instruction) because it provides a precise template for reasoning depth and style.
For scaling CoT, automated techniques like Auto-CoT cluster diverse questions and generate reasoning chains programmatically, achieving +2–3% accuracy gains across arithmetic, commonsense, and symbolic reasoning benchmarks without manual exemplar crafting.
Practical Framework: Should You Use Few-Shot?
Here’s a decision tree for your next prompt:
- Is the task ambiguous or format-critical? → Lean toward few-shot
- Are you using a reasoning model (o1/R1)? → Default to zero-shot; use few-shot only for format alignment
- Is the task highly structured with clear instructions? → Try zero-shot first
- Do you have specialized domain terminology? → Few-shot with domain-specific examples
- Are you token-constrained? → Minimize examples or use zero-shot
- Can you curate diverse, representative examples? → Few-shot with MMR-style selection
- Are you hitting systematic biases? → Apply calibration or switch to zero-shot
Conclusion
Few-shot prompting transformed what’s possible with language models—the ability to teach new tasks through examples alone is genuinely remarkable. But the technique isn’t a universal accelerator. It’s a precision tool that works brilliantly in the right contexts and adds overhead or introduces bias in others.
The rise of reasoning models adds another layer: as models develop more sophisticated internal reasoning capabilities, the role of few-shot shifts from “teaching logic” to “aligning output format.” The optimal prompting strategy increasingly depends on which model you’re targeting.
Master the mechanics—understand induction heads, apply strategic example selection, and know when to reach for zero-shot instead. That’s how you move from prompting by trial and error to prompting by design.