

OpenAI just announced GPT-5.5, and it’s not just another incremental release. This model represents a significant shift toward what they’re calling “agentic AI”—systems that don’t just answer questions but actually do work. For those of us in enterprise IT and consulting, this has real implications worth understanding.
The Agentic Shift: From Chatbot to Co-Worker
The headline capability of GPT-5.5 isn’t raw intelligence (though it has that). It’s autonomy. OpenAI describes the model as being able to “plan, use tools, check its work, navigate through ambiguity, and keep going.” You can hand it a messy, multi-part task and trust it to figure out the execution path.
This matters because enterprise workflows are rarely clean. They involve multiple systems, partial information, and decisions that require context accumulated over time. Previous models could assist with individual steps. GPT-5.5 is designed to own the loop.
The benchmark improvements reflect this:
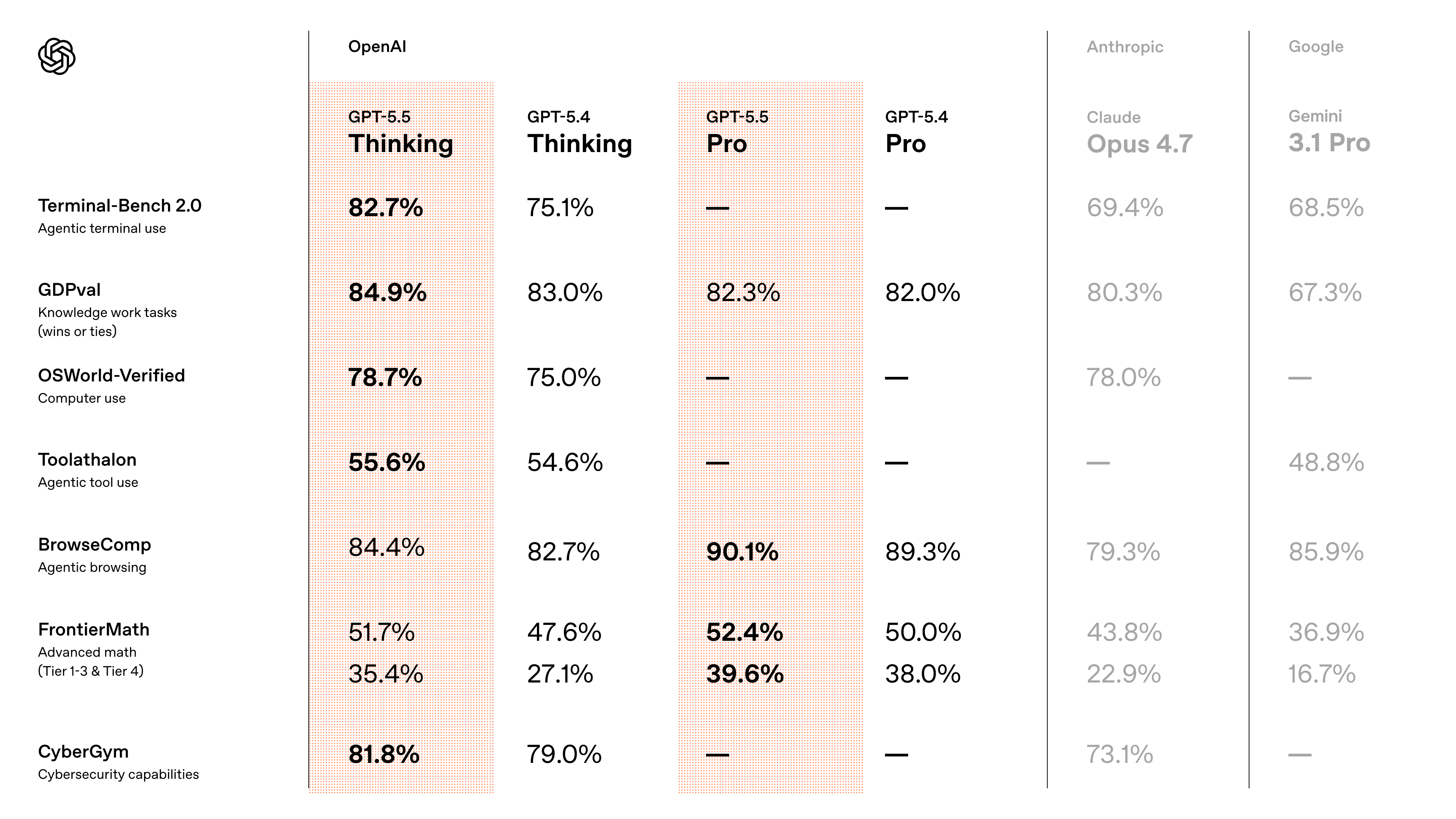
- Terminal-Bench 2.0 (complex command-line workflows): 82.7% vs 75.1% for GPT-5.4
- OSWorld-Verified (computer use in real environments): 78.7%
- Expert-SWE (long-horizon coding with ~20 hour median completion time): Improvement over GPT-5.4
These aren’t trivia benchmarks. They measure whether the model can operate autonomously in realistic conditions.
Coding: The Most Mature Use Case
Agentic coding is where GPT-5.5 really flexes. The model achieves state-of-the-art on Terminal-Bench 2.0 and scores 58.6% on SWE-Bench Pro (real GitHub issue resolution). More importantly, it does this while using fewer tokens than GPT-5.4—meaning it’s both smarter and more efficient.
One testimonial from OpenAI’s announcement stood out: Dan Shipper, founder of Every, described debugging an app for days before bringing in a senior engineer for a rewrite. He then rewound the clock to test GPT-5.5—could the model look at the broken state and produce the same kind of fix the engineer eventually landed on? GPT-5.4 couldn’t. GPT-5.5 could.
Another example: Pietro Schirano (CEO of MagicPath) had GPT-5.5 merge a branch with hundreds of frontend and refactor changes into a substantially-changed main branch. One shot. About 20 minutes.
For enterprise engineering teams, this changes the calculus on what you delegate. Junior engineer tasks? Obvious. But GPT-5.5 is starting to handle mid-level engineering work that requires understanding system architecture, predicting downstream effects, and maintaining consistency across a codebase.
Beyond Code: Knowledge Work and Computer Use
The same capabilities that make GPT-5.5 effective at coding make it effective at general computer use. OpenAI reports that 85% of their own company uses Codex (their agent product) weekly, across engineering, finance, communications, and product management.
Some specific examples from their announcement:
- Communications team: Built a scoring and risk framework for speaking requests, then validated a Slack agent to auto-handle low-risk requests while routing high-risk to humans.
- Finance team: Processed 24,771 K-1 tax forms (71,637 pages), accelerating the task by two weeks compared to the previous year.
- Go-to-Market: Automated weekly business reports, saving 5-10 hours per week.
On formal benchmarks:
- GDPval (knowledge work across 44 occupations): 84.9%
- Tau2-bench Telecom (complex customer-service workflows): 98.0% without prompt tuning
- FinanceAgent: 60.0%
- Investment Banking Modeling Tasks: 88.5%
The computer use story is particularly interesting. Combined with Codex’s screen-reading and interface-navigation capabilities, GPT-5.5 approaches something like a human operator: it can see what’s on screen, click, type, and move across applications with reasonable precision.
Cybersecurity: High Capability, High Stakes
OpenAI is treating GPT-5.5’s biological/chemical and cybersecurity capabilities as “High” under their Preparedness Framework—meaning significant capability that requires meaningful safeguards.
The benchmarks back this up:
- CyberGym: 81.8% (vs 73.1% for Claude Opus 4.7)
- Capture-the-Flags challenge tasks: 88.1%
OpenAI’s response is a mix of tighter controls and expanded access for legitimate defenders:
- Stricter classifiers around high-risk cybersecurity requests (they acknowledge this may annoy some users initially)
- Trusted Access for Cyber program with expanded access to GPT-5.5’s security capabilities for verified defenders
- Critical infrastructure partnerships with government agencies
The philosophical position here is interesting: powerful offensive capabilities are coming regardless, so the best strategy is democratized defense. Give verified defenders access to the same capabilities that bad actors will eventually have. Whether this holds up remains to be seen, but it’s a coherent position.
Scientific Research: A Real Co-Scientist
GPT-5.5 shows meaningful gains in scientific applications. On GeneBench (multi-stage scientific data analysis in genetics), it scores 25.0% vs 19.0% for GPT-5.4—notable because these tasks often correspond to multi-day projects for scientific experts.
The most striking claim: an internal version of GPT-5.5 with a custom harness helped discover a new proof about Ramsey numbers in combinatorics. The result was later verified in Lean. This isn’t just code generation—it’s a novel mathematical contribution in a core research area.
For enterprise R&D teams, the implication is that GPT-5.5 can meaningfully accelerate research workflows: not just explaining concepts or writing code, but proposing analyses, critiquing arguments, and working through the full loop from question to experiment to output.
Infrastructure: Same Speed, Higher Intelligence
One of the quieter achievements is that GPT-5.5 matches GPT-5.4’s per-token latency while being significantly more capable. Larger models are typically slower; OpenAI broke that relationship.
They achieved this through tight integration between model architecture and serving infrastructure, co-designed for NVIDIA GB200 and GB300 NVL72 systems. Interestingly, GPT-5.5 itself helped optimize the inference stack—including a 20% improvement in token generation from better load balancing heuristics.
The pricing reflects the efficiency gains:
- API: $5 per 1M input tokens, $30 per 1M output tokens (1M context window)
- GPT-5.5 Pro: $30 per 1M input, $180 per 1M output
- Batch/Flex: Half the standard rate
- Priority: 2.5x standard rate
Higher sticker price than GPT-5.4, but better results with fewer tokens. For most workloads, the effective cost should be comparable or lower.
Availability
As of today:
- ChatGPT: GPT-5.5 Thinking available to Plus, Pro, Business, and Enterprise. GPT-5.5 Pro available to Pro, Business, and Enterprise.
- Codex: GPT-5.5 available for Plus, Pro, Business, Enterprise, Edu, and Go plans with 400K context window. Fast mode available at 1.5x speed / 2.5x cost.
- API: Coming “very soon”
What This Means for Enterprise Strategy
Three takeaways:
-
Delegation thresholds are moving up. Tasks that previously required mid-level human expertise—complex debugging, multi-system workflows, document synthesis—are increasingly automatable. This changes staffing models and project scoping.
-
Computer use is becoming real. The combination of vision, tool use, and autonomous execution means AI can increasingly operate software the way humans do. This has implications for RPA, workflow automation, and integration strategy.
-
Security is a first-class concern. Models with strong offensive capabilities require serious governance. If you’re adopting frontier models, you need policies around prompt injection, data exfiltration, and capability boundaries—not just usage policies, but technical controls.
The agentic era is arriving faster than many expected. GPT-5.5 isn’t AGI, but it’s a meaningful step toward AI that does work rather than just assists with it. For enterprise leaders, the question isn’t whether to adopt—it’s how to do so thoughtfully.