I launched the Path of Progress app this week, and within hours, my inbox started filling up with a version of the same question: How did you build that? What’s involved? Where do I even start?
The honest answer is longer than most people expect. I’ve spent my career in IT infrastructure — networking, servers, storage, security operations, the systems that keep everything else running. That background gave me a solid foundation. But stepping into app development was like walking through a door into a building that turned out to be an entire city. The tooling, the patterns, the operational concerns, the sheer number of moving parts that have to interlock before a user taps a button on their phone and something actually happens — it’s a different ecosystem, with its own vocabulary, its own tribal knowledge, and a learning curve that is genuinely steep even if you already understand how packets traverse a network or how a SAN presents storage to a hypervisor.
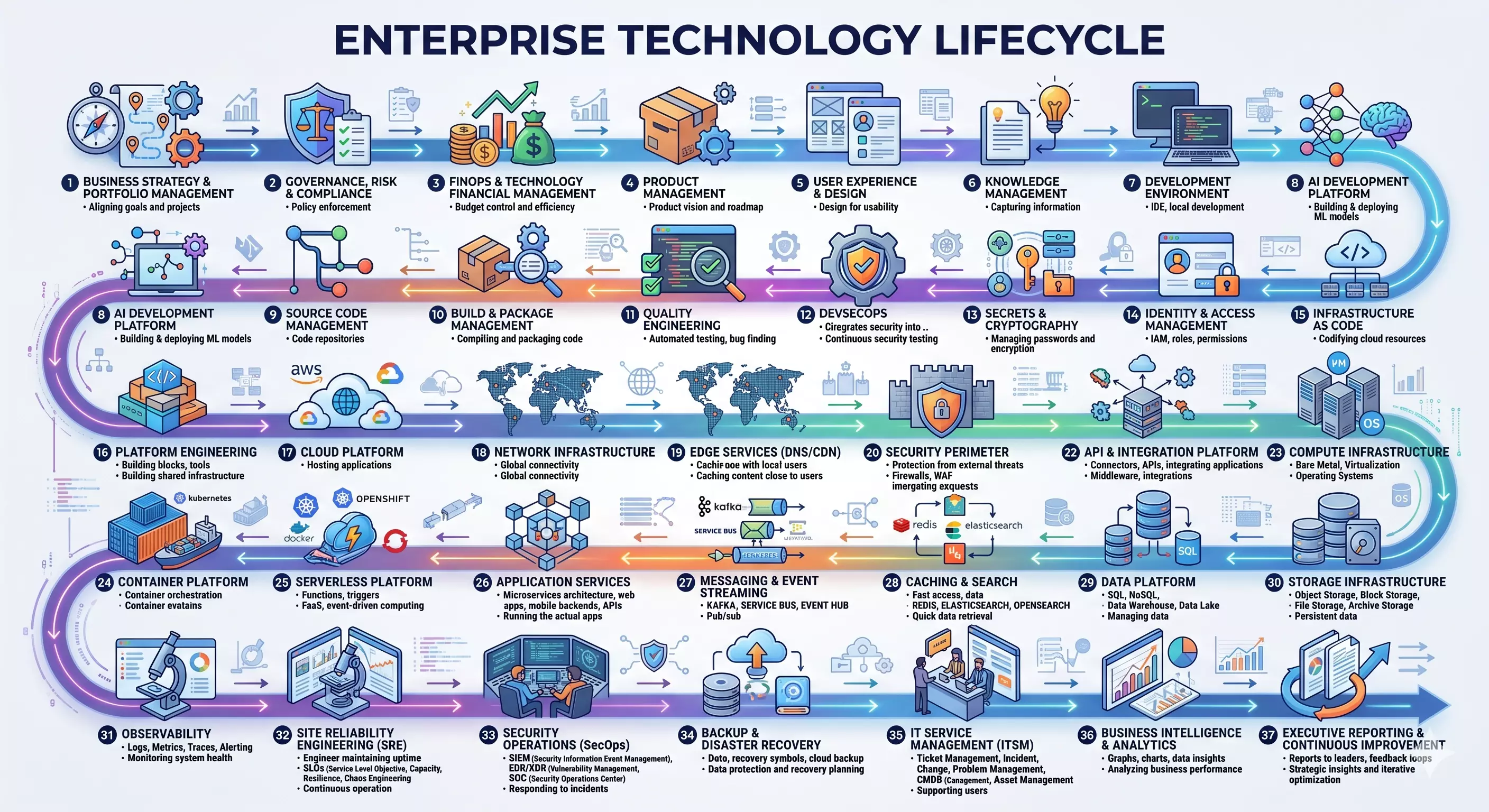
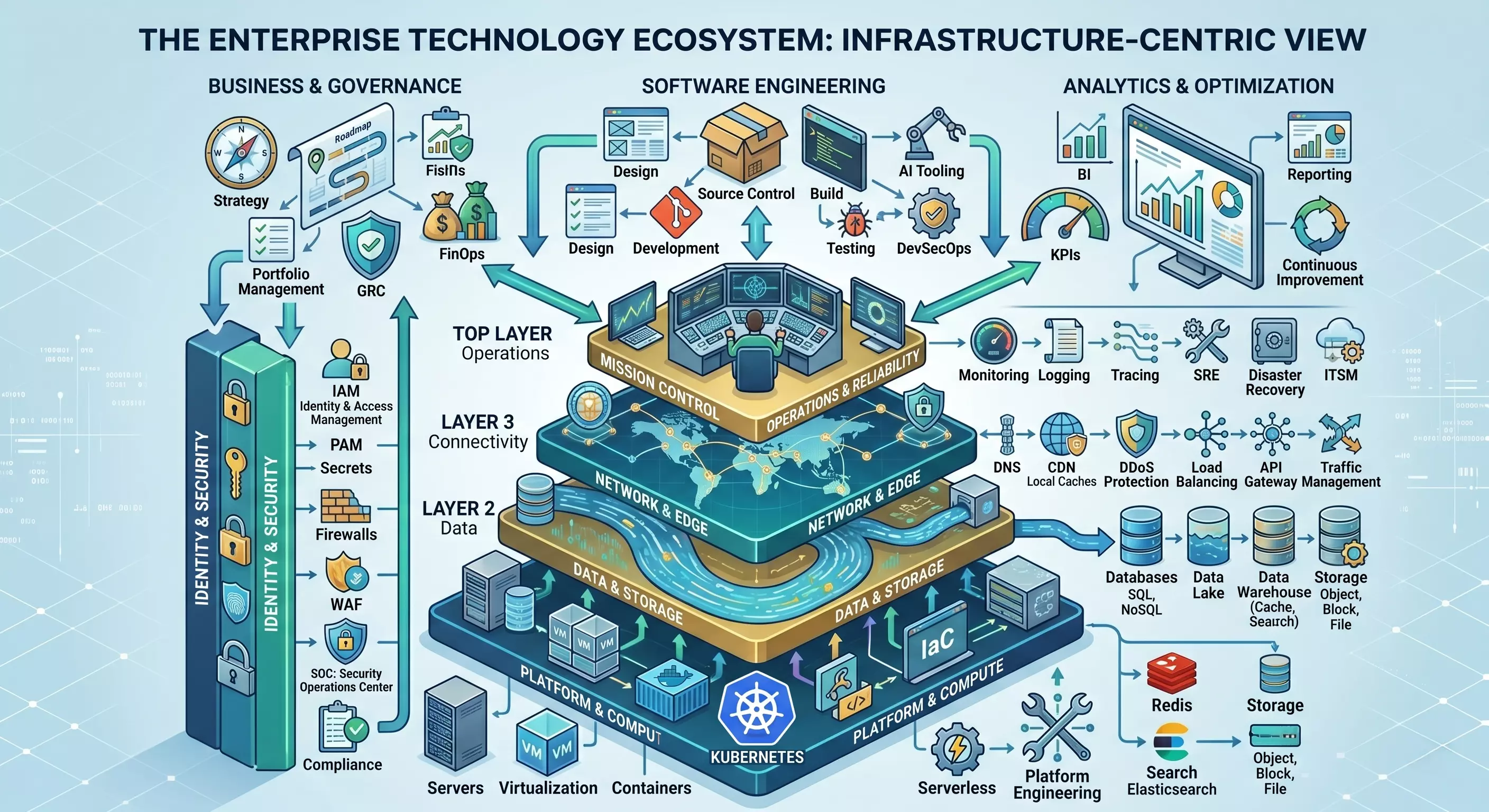
What follows is the map I wish someone had handed me. It’s not a tutorial — it’s a capability model. Thirty-three technology domains, organized into the eight towers that constitute the modern enterprise technology stack. Every one of them touches the lifecycle of an application, from the first line of code to the moment an incident gets resolved at 2 a.m. Some of them you’ll manage yourself. Some you’ll outsource to a cloud provider or a managed service. But none of them disappear just because you aren’t thinking about them.
The Scale Nobody Warns You About
Before walking through the towers, it’s worth pausing on the sheer scale of what’s out there. The CNCF Cloud Native Landscape — the interactive map maintained by the Cloud Native Computing Foundation — catalogs hundreds of projects and products across dozens of categories. The CNCF itself hosts nearly 200 projects, and Kubernetes alone has become the gravitational center of an ecosystem so large that no single person can claim expertise across all of it. OpenTelemetry, the observability instrumentation standard, graduated as the second-most-active CNCF project in May 2026, behind only Kubernetes.
On the DevOps tooling side alone, one comprehensive catalog from Spacelift identifies 73 distinct tools that teams commonly adopt across the pipeline — and that’s before you factor in the bespoke internal tooling that most organizations build on top. Studies show that 85% of teams use multiple monitoring tools alone, and tool sprawl — the organizational drag created by having too many overlapping tools with no clear ownership — has become a problem category in its own right.
The point isn’t that you need to master all of this. The point is that when you build an application, you’re implicitly making decisions in every one of these domains whether you realize it or not. Choosing not to think about your CDN strategy is itself a CDN strategy — the default one, where your users eat the latency. Choosing not to think about secrets management means your API keys are probably in a .env file committed to a repository somewhere. The map makes the implicit explicit.
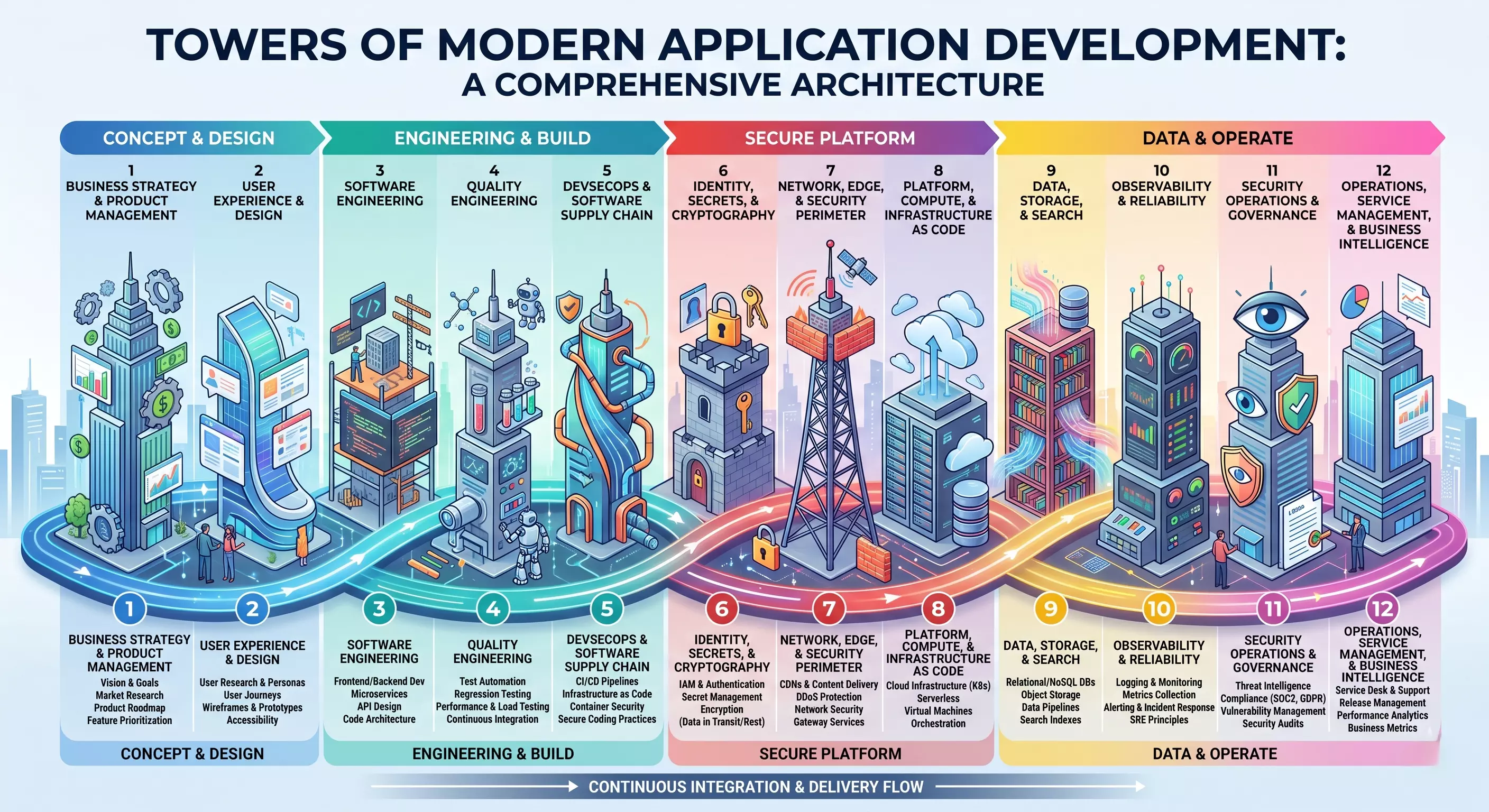
Tower 1: Business Strategy and Product Management
This is where software development starts, even though it doesn’t feel like engineering. Before you write a line of code, someone has to decide what to build, why it matters, and how to measure whether it worked. That someone might be you — especially if you’re a solo developer or a small team — and the discipline doesn’t go away just because you’re also the person writing the code.
Technology strategy is the exercise of deciding which platforms, languages, and architectures align with your business goals and your team’s actual capabilities. Pick a stack because it matches your constraints, not because it topped a Hacker News thread. Product roadmaps translate strategy into sequenced work. Feature prioritization is the art of saying no to most of the things you could build so you can actually ship the things that matter. Requirement management and user story management are the mechanisms that keep the gap between “what the customer needs” and “what the engineer builds” from widening silently over months.
Portfolio management, program management, and resource planning sit above individual products. They answer questions like: across all the things we’re building, are we spending our budget and our people’s time on the right mix? For a solo developer launching a side project, this might be a spreadsheet. For a 200-person engineering org, it’s an entire function with dedicated tooling — Jira Portfolio, Aha!, ProductBoard, or Linear’s roadmap features.
The reason this tower matters for an infrastructure person learning to build apps is that infrastructure rarely requires you to think this way. Infrastructure is mostly reactive — keep the lights on, respond to tickets, upgrade when the vendor EOLs the version. Product development inverts that. You’re choosing what to create from a blank canvas, and the cost of building the wrong thing is months of work that delivers no value.
Tower 2: User Experience and Design
If you come from infrastructure, this tower is an entirely foreign discipline. Nobody wireframes a VLAN design. Nobody conducts user interviews to determine how a firewall rule should feel.
But in app development, UX research and design are non-negotiable. User interviews and user testing reveal the gap between what you think users want and what they actually need — a gap that, in my experience, is always wider than you expect. Accessibility testing ensures your application works for users with visual, motor, or cognitive disabilities, and increasingly, accessibility compliance (WCAG 2.1 AA) isn’t optional — it’s a legal requirement in many jurisdictions. Journey mapping traces the complete path a user follows through your application, exposing friction points that individual screen designs miss.
On the design side, UI design is the visual layer — layout, typography, color, interaction patterns. Design systems are the engineering discipline applied to design: component libraries, spacing rules, color tokens, and documentation that ensure visual consistency across an application as it grows. Figma is the dominant tool here as of mid-2026, with design tokens increasingly bridging the gap between design files and code through tools like Style Dictionary or Tokens Studio.
Prototyping lets you test interactions before you build them. Design handoff is the process of translating a designer’s intent into specifications an engineer can implement — spacing values, responsive breakpoints, animation timing, interaction states. This is where things break down in practice. A designer delivers a pixel-perfect mockup; the engineer discovers it doesn’t account for a loading state, an error state, an empty state, or what happens when the user’s name is 47 characters long. The handoff discipline exists to close those gaps before they become bugs.
Tower 3: Software Engineering
This is the tower most people think of when they hear “app development,” but it’s one of eight, and even within it, the scope is broader than outsiders expect.
The development environment is your starting point. Your IDE (VS Code, JetBrains, Cursor, Zed) is where you spend most of your waking hours. AI coding assistants — GitHub Copilot, Claude Code, Cursor’s inline suggestions — have moved from novelty to default tooling in under three years; as of mid-2026, it’s unusual to find a professional developer who doesn’t use one. Local debugging, linting, formatting, and developer tooling round out the workstation. The goal is a local environment that matches production closely enough that the thing you build on your laptop actually works when it ships.
Development standards are the agreements a team makes about how to write code together: coding standards (formatting, naming conventions, patterns), branching strategies (trunk-based development vs. Gitflow vs. feature branches), and development workflows (how code moves from an engineer’s branch to a pull request to a merged commit). These feel bureaucratic until you’ve worked on a codebase without them, at which point you discover what entropy looks like in code.
Source code management is fundamentally Git. Git repositories, branching, merging, tagging — these are the version control primitives. But the collaboration layer on top of Git is where the real work happens: pull requests (or merge requests, depending on your platform), code reviews, and repository governance. A pull request isn’t just a mechanism for merging code; it’s a communication artifact. The review process is where institutional knowledge transfers, where bugs get caught before they reach users, and where junior engineers learn the codebase’s conventions by seeing how seniors evaluate changes.
Repository security includes branch protection rules (preventing direct pushes to main), commit signing (cryptographically proving who wrote a change), and repository permissions (controlling who can read, write, and administer a repo). These feel like overhead until your first security incident.
Build and package management is the machinery that turns source code into deployable artifacts. Compilation, packaging, and build automation — whether you’re using webpack, Vite, Gradle, or go build — transform your development-time code into something a runtime can execute. Dependency management is where the software supply chain starts: your application depends on open-source libraries, those libraries depend on other libraries, and that tree of transitive dependencies is both the reason modern development moves fast and the reason a single compromised package can cascade into a supply chain attack. Package registries (npm, PyPI, Maven Central, crates.io) host these dependencies; artifact management systems like Artifactory or GitHub Packages store your built artifacts and container images.
Then there’s AI-assisted development, which has become its own subdomain. Code generation, documentation generation, test generation, refactoring assistance — these are no longer experimental features. They’re integrated into the daily workflow. The shift isn’t just productivity; it’s changing which skills matter. The ability to write a clear prompt that constrains an AI’s output toward a correct implementation is becoming as important as the ability to write the code from scratch. AI operations — model deployment, prompt management, model monitoring, AI governance — add yet another layer when your application itself uses AI features.
Tower 4: Quality Engineering
“Testing” sounds like one activity. It’s actually an entire discipline with its own specializations, tooling, and career paths.
Unit testing verifies that individual functions or components behave correctly in isolation. Integration testing verifies that multiple components work together — that your API layer correctly reads from and writes to your database, for instance. API testing validates that your endpoints return the correct responses, handle edge cases, and enforce authentication. End-to-end testing simulates a real user’s journey through the application from start to finish, typically running in a browser via tools like Playwright or Cypress.
Each of these testing types catches a different class of bug, and none of them is sufficient alone. A codebase with 100% unit test coverage and zero integration tests can still break catastrophically in production because the units work perfectly in isolation but fail when they interact with each other through a real database or a real network call.
Performance engineering is a distinct discipline from functional testing. Load testing measures how your application performs under expected traffic volumes. Stress testing pushes past expected volumes to find the breaking point. Capacity testing determines whether your infrastructure can handle projected growth. The tools — k6, Gatling, Locust, JMeter — generate synthetic traffic patterns that simulate real-world usage. The insights they produce are only as good as the scenarios you model, which means performance engineering requires understanding your production traffic patterns well enough to reproduce them.
Test automation is the practice of running these tests automatically — typically on every commit, as part of a CI/CD pipeline. Test data management is the underappreciated problem of getting realistic but compliant data into your test environments. You can’t test with production data if that data contains PII, but you can’t test with obviously fake data and expect your tests to catch the bugs that only surface with real-world data shapes. Synthetic data generation and data masking solve this, but neither is trivial.
Tower 5: DevSecOps and the Software Supply Chain
DevSecOps is the practice of embedding security into every phase of the development lifecycle rather than bolting it on at the end. The “shift left” metaphor — move security earlier in the pipeline — has been repeated so often it’s become a cliché, but the underlying principle is sound: a vulnerability caught during a code review costs orders of magnitude less to fix than one discovered in production.
CI/CD — Continuous Integration and Continuous Delivery — is the pipeline that automates the journey from committed code to deployed application. Continuous integration means every developer’s code is merged into a shared branch frequently (at least daily), with automated builds and tests running on every merge. Continuous delivery means the pipeline can deploy any successful build to production at any time, with the actual deployment triggered either automatically (continuous deployment) or by a human decision (continuous delivery). GitHub Actions, GitLab CI, CircleCI, and Jenkins are the dominant pipeline platforms.
Security testing is embedded into this pipeline. SAST (Static Application Security Testing) analyzes source code for vulnerabilities without executing it — think of it as a security-focused linter. DAST (Dynamic Application Security Testing) tests the running application by probing its endpoints for common vulnerabilities like SQL injection and cross-site scripting. SCA (Software Composition Analysis) scans your dependency tree to identify known vulnerabilities in third-party packages — the library you pulled from npm six months ago might have a critical CVE published against it today. Secret scanning catches credentials, API keys, and tokens that were accidentally committed to source code, which happens far more often than anyone wants to admit.
The software supply chain has become a first-class security concern. Executive Order 14028 made SBOMs — Software Bills of Materials, machine-readable inventories of every component in your software — a requirement for federal software suppliers. The EU Cyber Resilience Act extends similar requirements across European markets. An SBOM in CycloneDX or SPDX format, generated as part of every build, signed and attached to the artifact, is becoming the baseline expectation rather than an advanced practice. SLSA Build L3 provenance — which requires a hardened build platform and non-falsifiable provenance documents — represents the current bar for federal procurement. Artifact signing, dependency validation, and provenance tracking ensure that the thing you deploy is the thing you built, and that the things it depends on haven’t been tampered with.
Tower 6: Identity, Secrets, and Cryptography
Identity and access management is the domain that determines who can do what, and it’s far more complex than “username and password.”
Workforce identity covers how your employees authenticate. SSO (Single Sign-On) lets users authenticate once and access multiple applications. MFA (Multi-Factor Authentication) requires a second verification factor — a TOTP code, a hardware key, a push notification — to prevent credential theft from being sufficient for account compromise. Federation connects identity providers across organizational boundaries. Conditional access policies enforce context-dependent rules: you can access this application from a managed device on the corporate network, but from an unmanaged device on public Wi-Fi, you need to step up to a hardware key.
Customer identity (CIAM) is a different problem entirely. Your application’s end users authenticate through social login, email/password, passwordless flows, or B2B federation. The tooling — Auth0, Clerk, Supabase Auth, Firebase Authentication, AWS Cognito — handles the user-facing authentication flows, session management, and token lifecycle. Getting this right is genuinely hard. Getting it wrong means your users’ credentials are at risk, and the reputational damage is existential for a product-stage company.
Privileged access management (PAM) controls access to high-impact systems — production databases, cloud consoles, infrastructure management planes. JIT access (Just-In-Time) grants elevated privileges only when needed and revokes them automatically, reducing the window during which a compromised privileged account can do damage. Session recording creates an audit trail of what privileged users actually did during elevated sessions.
Authorization — what an authenticated user is allowed to do — has its own models. RBAC (Role-Based Access Control) assigns permissions to roles and assigns roles to users. ABAC (Attribute-Based Access Control) evaluates attributes of the user, the resource, and the environment to make access decisions. Policy-based access externalizes authorization logic into policy engines like Open Policy Agent (OPA) or Cedar, separating the “who can do what” decision from the application code.
Secrets management protects the API keys, credentials, database passwords, and tokens your application needs at runtime. HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, and Doppler are the common platforms. The alternative — hardcoding secrets in configuration files or environment variables committed to source control — is the path to a breach. Key management (KMS, HSM) handles cryptographic keys for encryption operations. Certificate management handles the TLS certificates that encrypt your traffic and the code-signing certificates that prove your artifacts haven’t been tampered with. Encryption at rest, encryption in transit, and application-layer encryption are the three layers that protect data regardless of where it lives.
Tower 7: Network, Edge, and Security Perimeter
This is the tower where my infrastructure background was most directly transferable — and also where I was most surprised by how different the application-layer perspective is from the infrastructure-layer perspective.
Network infrastructure — LAN, WAN, SD-WAN, VPN, BGP, OSPF, VLANs, data center fabrics — is the foundation. If you’ve run networks, you know this domain. What changes in app development is the altitude at which you interact with it. You stop configuring individual switches and start consuming networking as a service: VPCs in AWS, VNets in Azure, overlay networks in Kubernetes. The primitives are the same — subnets, routing tables, access control lists — but the interfaces are Terraform manifests and YAML files, not CLI sessions on a Cisco switch.
Network services — DNS, DHCP, IPAM, NTP — are infrastructure staples. In the application world, DNS becomes the front door. Authoritative DNS serves your domain’s records. Recursive DNS resolves queries for your users. GeoDNS routes users to the nearest point of presence. Getting DNS right — low TTLs during migrations, proper CAA records for certificate issuance, DNSSEC for integrity — is a prerequisite for everything else.
CDN (Content Delivery Network) services — Cloudflare, Fastly, AWS CloudFront, Akamai — cache and serve your static assets from edge locations close to your users. Edge compute takes this further, running application logic at the CDN edge rather than in a centralized data center. DDoS protection at both Layer 3/4 (volumetric attacks) and Layer 7 (application-layer attacks) is table stakes for any application exposed to the internet.
The security perimeter is where infrastructure and application security converge. Network firewalls, cloud firewalls (security groups, NACLs), and next-generation firewalls (NGFWs) control traffic flow. WAF (Web Application Firewall) inspects HTTP traffic for malicious payloads — SQL injection, XSS, path traversal. Bot protection distinguishes legitimate users from automated scrapers, credential-stuffing bots, and inventory-hoarding scripts. API security — rate limiting, schema validation, authentication enforcement — protects the machine-to-machine interfaces that make up an increasing percentage of application traffic.
Zero Trust architecture has moved from buzzword to implementation reality, though slowly. The principle is simple: never trust, always verify. No implicit trust based on network location. Every access request is authenticated, authorized, and encrypted regardless of whether it originates inside or outside the corporate network. ZTNA (Zero Trust Network Access) replaces VPNs with per-application, identity-aware access controls. SSE (Security Service Edge) and SASE (Secure Access Service Edge) bundle ZTNA with cloud security gateways, cloud access security brokers, and data loss prevention into a unified platform. Gartner projects that only about 10% of large enterprises will have a mature, measurable zero trust program in place by 2026, up from less than 1% in 2023 — which tells you how hard the actual implementation is despite near-universal intent. Ninety-six percent of organizations favor a zero trust approach, but fewer than 10% have reached “Advanced” or “Optimal” maturity.
Intrusion detection and prevention (IDS/IPS) and network detection and response round out the perimeter, monitoring traffic for patterns that indicate compromise.
Tower 8: Platform, Compute, and Infrastructure as Code
This tower is where an infrastructure engineer feels most at home — and where the modern evolution is most dramatic.
Physical infrastructure — bare metal servers, hypervisors, hardware lifecycle management — still matters for high-performance workloads, regulatory requirements, or cost optimization at scale. But the center of gravity has shifted decisively to virtual and cloud infrastructure. VMware, Hyper-V, and KVM still run enterprise workloads, but the action is in the cloud platforms: AWS, Azure, and Google Cloud. Hybrid and multi-cloud architectures are the norm for organizations above a certain size, and cloud governance — landing zones, guardrails, policy enforcement — is the discipline that keeps cloud sprawl from becoming cloud chaos.
Container platforms have redefined how applications are packaged and deployed. Docker established the container format. Kubernetes became the orchestration layer — handling cluster management, scheduling, scaling, and service discovery. The Kubernetes ecosystem is vast: service meshes (Istio, Linkerd), ingress controllers (NGINX, Traefik, Envoy Gateway), operators, custom resource definitions, and the entire CNCF landscape of graduated and incubating projects. Understanding Kubernetes at a production level isn’t a weekend project; it’s a months-long investment that touches networking, storage, security, observability, and cost management simultaneously.
Serverless platforms — AWS Lambda, Azure Functions, Google Cloud Functions — abstract away the server entirely. You write a function, define a trigger (an HTTP request, a queue message, a cron schedule), and the platform handles scaling, including scaling to zero when there’s no traffic. The trade-off is control: you gain operational simplicity but lose the ability to fine-tune the runtime environment, and cold starts — the latency hit when a function hasn’t been invoked recently — can be a real performance concern for latency-sensitive workloads.
Infrastructure as Code (IaC) is the practice of defining infrastructure in declarative configuration files rather than clicking through console GUIs. Terraform (now OpenTofu, after HashiCorp’s license change), Pulumi, AWS CloudFormation, and Azure Bicep are the primary tools. IaC enables reproducibility (spin up identical environments on demand), auditability (infrastructure changes go through pull requests, just like code changes), and disaster recovery (rebuild your entire infrastructure from version-controlled definitions). GitOps takes this further: your Git repository becomes the single source of truth for infrastructure state, and a reconciliation controller (Argo CD, Flux) continuously ensures the running infrastructure matches the declared state.
Platform engineering is the discipline that ties this all together. It’s the practice of building an internal developer platform — a set of self-service capabilities that let application developers provision infrastructure, deploy code, and operate their services without filing tickets or waiting for an infrastructure team. Golden paths are the pre-approved workflows that encode organizational best practices: “deploy a new microservice” becomes a template that produces a service with CI/CD, monitoring, logging, and security policies already configured. By 2026, 80% of large software engineering organizations are expected to have platform engineering teams, though roughly 70% of platform initiatives fail to achieve meaningful adoption — usually because they optimize for the platform team’s convenience rather than the developer’s experience.
Tower 9: Data, Storage, and Search
Every application is, at its core, a system for storing, transforming, and retrieving data. The infrastructure beneath that premise is its own ecosystem.
Databases span a spectrum. SQL databases (PostgreSQL, MySQL, SQL Server) provide relational schemas, ACID transactions, and a query language that’s been refined over decades. NoSQL databases (MongoDB, DynamoDB, Cassandra) trade some of those guarantees for flexibility in schema design, horizontal scalability, or specific access patterns. Time-series databases (InfluxDB, TimescaleDB) optimize for append-heavy workloads like metrics and IoT sensor data. Choosing the right database isn’t a religious decision — it’s a question of which trade-offs your application’s access patterns require.
Data services extend beyond operational databases. Data lakes (built on object storage like S3, queried via engines like Athena, Presto, or Spark) store large volumes of raw data in its original format. Data warehouses (Snowflake, BigQuery, Redshift) store structured, transformed data optimized for analytical queries. Data marts are subsets of a warehouse, scoped to a specific business function. Data governance — cataloging, lineage tracking, and data quality monitoring — ensures you know what data you have, where it came from, and whether it’s reliable.
Storage infrastructure is the foundation: object storage (S3 and its compatibles) for unstructured data, block storage (SAN, cloud volumes like EBS) for database backends, file storage (NAS, EFS, Azure Files) for shared file systems, and archival storage (Glacier, Archive Storage) for long-term retention at reduced cost. Immutable storage — write-once, read-many — is increasingly important for compliance and ransomware resilience.
Caching sits between your application and your data store, absorbing repeated reads and reducing database load. Redis is the dominant in-memory data store, serving double duty as both a cache and a lightweight message broker. Memcached remains a simpler alternative for pure key-value caching workloads.
Search has evolved from full-text keyword matching into a multi-modal capability. Elasticsearch and OpenSearch handle traditional full-text and structured search. Vector search — storing and querying high-dimensional embeddings generated by machine learning models — enables semantic search, recommendation systems, and retrieval-augmented generation (RAG) for AI applications. This is the layer where your application stops matching keywords and starts understanding meaning, and it’s one of the areas where AI integration has changed the data infrastructure landscape most dramatically.
Tower 10: Observability and Reliability
You can’t operate what you can’t see. Observability is the discipline that makes a running application transparent to the people responsible for keeping it running.
The three pillars are metrics, logs, and traces. Metrics are numerical measurements sampled over time — CPU utilization, request latency, error rates, queue depth, business KPIs like signup conversions. Logs are timestamped records of discrete events — a user logged in, a payment failed, an exception was thrown. Traces follow a single request as it propagates through a distributed system, showing exactly which services it touched, how long each hop took, and where the latency accumulated.
OpenTelemetry has become the de facto standard for instrumenting applications to produce all three signal types. With 48.5% of organizations already using it and another 25% planning to, OpenTelemetry provides vendor-neutral instrumentation that you write once and route to whatever backend you choose — Datadog, Grafana Cloud, New Relic, Dynatrace, or self-hosted Prometheus and Jaeger. The practical value is portability: you can switch observability vendors without re-instrumenting your application. Companies like Shopify have reported 75% reductions in incident resolution time after adopting distributed tracing, and the cost savings from moving to efficient tracing implementations have been substantial — one engineering team achieved 72% cost savings while moving from 5% sampled traces to 100% APM coverage across all environments.
Alerting connects observability to action. Threshold alerts fire when a metric crosses a boundary. Intelligent alerting uses anomaly detection to identify unusual patterns without manually defining thresholds for every metric. The challenge isn’t creating alerts — it’s creating alerts that are actionable, not noisy. Alert fatigue — too many low-value notifications — is the fastest way to guarantee that the alert which actually matters gets ignored.
Site Reliability Engineering (SRE) builds on observability to establish quantified reliability targets. SLAs (Service Level Agreements) are contractual commitments to customers. SLOs (Service Level Objectives) are internal targets, typically more aggressive than SLAs, that drive engineering prioritization. Error budgets are the inverse of SLOs: if your SLO is 99.9% availability, your error budget is 0.1% — roughly 43 minutes of downtime per month. When you’ve consumed your error budget, you stop shipping features and focus on reliability. This mechanism transforms reliability from an abstract aspiration into a quantified resource that trades off against velocity.
Capacity management — forecasting demand, scaling infrastructure proactively — prevents the 3 a.m. page that comes from running out of headroom during a traffic spike. Resilience testing and chaos engineering (deliberately injecting failures into production to verify that systems degrade gracefully) validate that your redundancy actually works. Netflix’s Chaos Monkey — which randomly terminates production instances — is the canonical example, but the practice has matured into a discipline with frameworks like Gremlin and LitmusChaos.
Tower 11: Security Operations and Governance
Security operations is where the infrastructure-side and application-side security concerns converge into a unified defense.
Vulnerability management — scanning, remediation, risk scoring — is continuous. Your infrastructure, your containers, your application dependencies, and your running application all need to be scanned on a regular cadence, and the vulnerabilities that surface need to be prioritized by exploitability and blast radius, not just CVSS score. A medium-severity vulnerability in an internet-facing authentication service matters more than a critical-severity vulnerability in an air-gapped internal tool.
Endpoint security — EDR (Endpoint Detection and Response), XDR (Extended Detection and Response), and device compliance — protects the machines your developers and operations staff use daily. A compromised developer laptop with access to production credentials is an attack vector that bypasses every network-layer defense you’ve built.
SIEM (Security Information and Event Management) aggregates logs and events from across your infrastructure, correlates them, and surfaces patterns that indicate compromise. SOC (Security Operations Center) is the team — or the function, if you can’t afford a dedicated team — that investigates those alerts, hunts for threats proactively, and responds to incidents.
Governance, Risk, and Compliance (GRC) provides the organizational framework. Policy management and architecture governance define the rules. Risk management — technology risk, security risk, third-party risk — quantifies exposure. Compliance frameworks (ISO 27001, SOC 2, HIPAA, PCI DSS, NIST, CIS) are the external standards your organization must meet, and audit — maintaining audit trails and collecting evidence — is what proves you actually met them.
Tower 12: Operations, Service Management, and Business Intelligence
The final tower covers the operational machinery that keeps everything running after deployment and the analytical layer that tells you whether any of it is working.
Backup and disaster recovery is the discipline that infrastructure engineers know intimately. Infrastructure backup, database backup, and increasingly SaaS backup (because your data in Salesforce or Microsoft 365 is your responsibility, not the vendor’s) form the protection layer. Disaster recovery — regional failover, business continuity planning — is the plan for when an entire region or data center goes offline. Recovery testing — actually running your DR plan, not just documenting it — is what separates organizations that survive outages from organizations that discover during an outage that their backups were corrupted six months ago.
IT Service Management (ITSM) is the operational discipline that governs how technology services are delivered and supported. Ticket management and service requests handle the flow of user-facing work. Incident management — major incidents, escalations, postmortems — is the structured response to things going wrong. Change management (CAB processes, release approvals) is the governance that prevents well-intentioned changes from breaking production. Problem management — root cause analysis, known error databases — looks past individual incidents to identify systemic issues. Asset management and the CMDB (Configuration Management Database) maintain the authoritative record of what hardware and software you own, where it is, and how it relates to everything else.
Knowledge management — architecture documentation, operational runbooks, SOPs, wikis, knowledge bases — is the infrastructure that prevents institutional knowledge from existing solely in a senior engineer’s head. When that engineer leaves, the knowledge goes with them unless it’s been captured in a format that’s discoverable and maintained.
Business intelligence and analytics close the loop. Operational reporting and executive dashboards provide visibility into system health. KPI tracking and product analytics measure whether the thing you built is achieving its intended business outcome. Data science — predictive analytics, machine learning — extracts forward-looking insights from historical data. This is also where FinOps lives: the practice of managing cloud costs with the same rigor you apply to any other line item. Organizations without FinOps programs waste 32–40% of their cloud spend on idle resources, over-provisioned instances, and orphaned storage. Mature FinOps programs reduce that to 15–20%, but only 23% of organizations consider themselves “highly efficient” in managing cloud costs.
The Map Is the Point
Nobody walks into this with expertise across all 33 domains. I came from IT infrastructure, security architecture, and IT operations, which meant networking, storage, identity and access management, security operations, and ITSM were familiar ground — but frontend frameworks, design systems, and CI/CD pipeline syntax were entirely new. Someone coming from a design background has the opposite profile: UX research and prototyping are second nature, but container orchestration and secrets management are foreign territory. A self-taught developer shipping their first side project might be starting fresh across the board. Everyone enters this landscape with a different slice of coverage and a different set of blind spots.
That’s exactly why the map matters. The 33 domains aren’t a checklist to complete before you’re allowed to build software. They’re the terrain you’re operating in whether you’ve surveyed it or not. When an application works on your laptop but breaks in production because a security group is blocking the database connection, that’s the network infrastructure domain asserting itself. When your API is fast from your office but slow from another continent, that’s the edge services domain. When a secret gets committed to source control and ends up in a breach notification, that’s secrets management. These domains don’t wait for you to learn them — they surface as incidents when you haven’t.
The practical approach isn’t mastery across all 33. It’s knowing they exist, understanding which ones your application depends on most heavily, and making deliberate decisions about which you’ll learn deeply, which you’ll delegate to a managed service, and which you’ll revisit as your application scales. A solo developer launching a first product can lean heavily on managed services — a platform like Vercel or Railway absorbs the compute, CDN, and deployment domains. A team scaling to production traffic across multiple regions will eventually need to engage with those domains directly.
The learning curve is real regardless of where you start. But the curve gets less steep once you can see the full shape of the terrain — once you know which questions to ask, even when you don’t yet have the answers. That’s the difference between building something that works and building something that lasts.