

In January 2025, a Virginia man named Joseph Roberson filed suit against Acxiom in the U.S. District Court for the Eastern District of Virginia (1:25-cv-00165). When the plaintiffs exercised their right of access, the report that came back from Acxiom was roughly 100 pages long. It included his Social Security number, decades of address history, and — more uncomfortably — categorical assessments the complaint described in the company’s own product language: “diet and fitness” habits, “ethnicity/religion,” and an algorithmically derived “assimilation level.” The same complaint flagged that Acxiom maintains a federal supply contract with the U.S. General Services Administration to sell personally identifiable data to government buyers.
The court eventually dismissed the suit. Acxiom won on the narrow legal question of whether two Virginia statutes covered the conduct alleged — the court said it was “troubled by the extensive allegations” but found they didn’t state a claim under those particular laws. Along the way, though, Acxiom’s own filings confirmed, on the record, the categories of personal information the company sells about ordinary Americans: names, personal identifiers, personal characteristics, real and personal property, buying activity, internet activity, geolocation, employment, education, and inferences. All of it linked together by an in-house identity resolution product Acxiom markets as Real ID.
Acxiom won the motion. The dossier didn’t go away. That is the through-line of this series: most of what is uncomfortable about the data broker economy is not illegal. It is the default mode of operation for an industry that has spent more than five decades — Acxiom has been compiling consumer data since 1969 — quietly building a parallel record of your life that you cannot see, did not consent to, and almost certainly cannot fully delete.
What a “Data Broker” Actually Is (And Isn’t)
A data broker is a company whose business model is to collect, link, enrich, and sell information about people without ever having a direct relationship with the people that information is about. That last clause is the whole point. Your bank knows you because you opened an account. Your airline knows you because you bought a ticket. Acxiom knows you because it bought, scraped, or inferred you into existence from records you never knowingly handed it.
Three useful distinctions before going further:
- Data brokers are not the same as credit bureaus, but they overlap. Experian, Equifax, and TransUnion are credit bureaus — regulated under the U.S. Fair Credit Reporting Act when the data is used for credit, insurance, employment, or housing decisions. The same three companies also run large, unregulated marketing and identity-resolution businesses on the side. The structural maneuver that lets them do this is worth naming: the bureaus claim FCRA and Gramm-Leach-Bliley exemptions for the regulated lines, then place explicit disclaimers on their commercial marketing products — text along the lines of “this data is not to be used for credit eligibility” — to keep that side of the house out of FCRA’s reach and, in many states, out of state deletion regimes designed for consumer reporting agencies. The FCRA only covers the regulated use; the rest is data brokerage operating in a quieter legal lane.
- Data brokers are not ad-tech platforms, but they feed them. Facebook and Google primarily monetize attention on their own surfaces. Brokers feed the outside of those walled gardens: the audience segments, identity graphs, and offline-to-online matches that let marketers find you across the open web.
- Data brokers are not “people-search sites,” but the people-search sites are a retail front for the same data. Spokeo, BeenVerified, and the like are mostly resellers of records aggregated upstream by larger players.
Once you have that taxonomy, the U.S. market is easier to see.
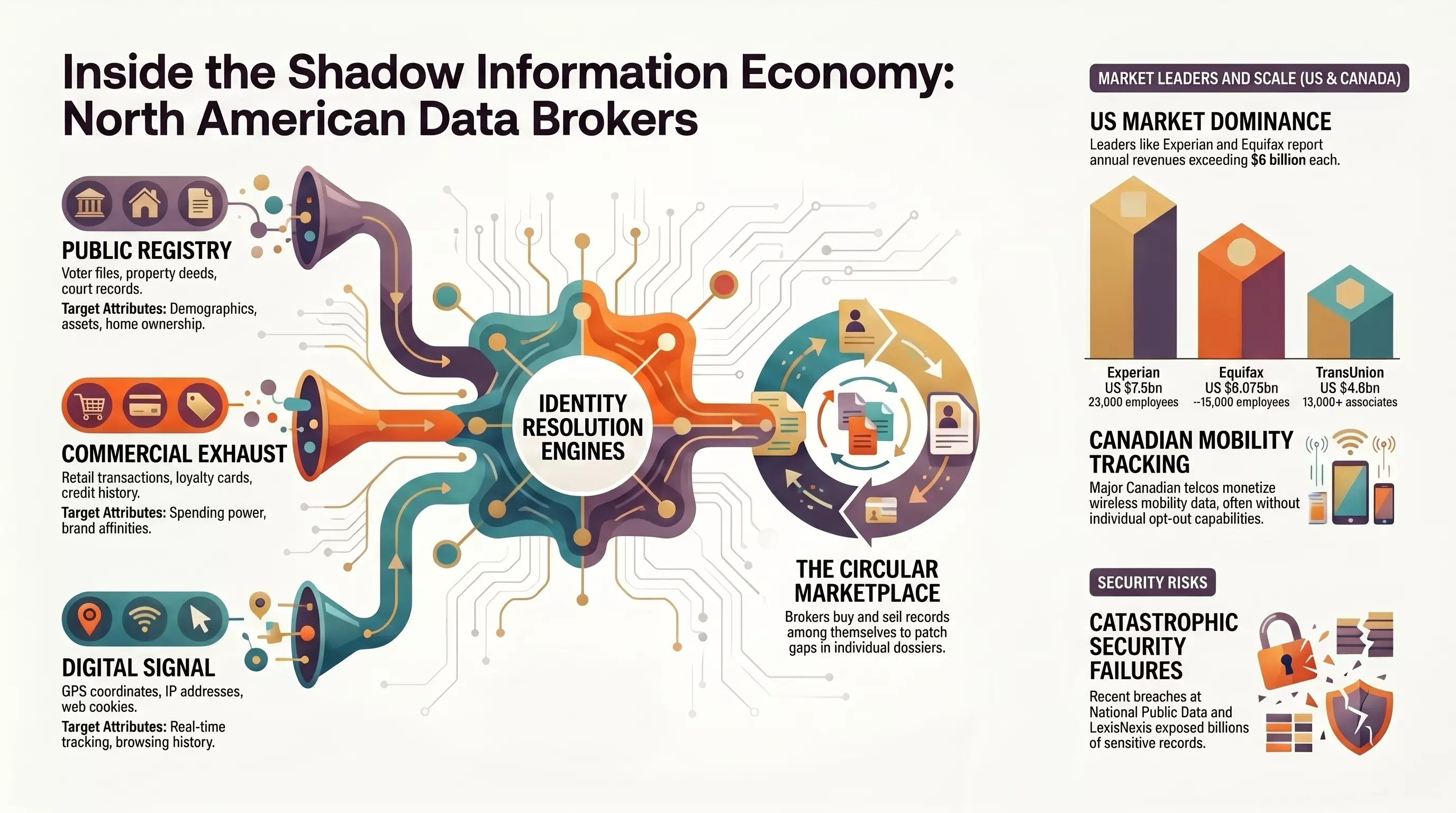
The U.S. Titans
The American data broker market is structurally concentrated. A handful of firms account for the overwhelming majority of revenue, and they have all evolved past simple “list resale” into what the industry calls a layered stack: ingest raw data, normalize it into person and household graphs, enrich those graphs with thousands of inferred attributes, then monetize through enterprise subscriptions and high-volume APIs.
| Rank | Broker | 2025 Revenue / Scale | Primary Data Domains |
|---|---|---|---|
| 1 | Experian | US$7.5B (FY25); 23,000 employees | Consumer credit, identity/fraud, marketing audiences, healthcare |
| 2 | Equifax | US$6.075B (2025); ~15,000 employees | Consumer credit, income/employment verification, business info |
| 3 | TransUnion | US$4.6B (2025); 13,000+ associates | Credit, identity graphs (TruAudience), public records, tenant screening |
| 4 | LexisNexis Risk Solutions | £3.336B segment (2025) | Fraud, financial crime, insurance, government/public safety |
| 5 | Verisk | US$3.073B (2025); ~8,000 employees | Insurance underwriting, geospatial, 1.9B+ claims records |
| 6 | Dun & Bradstreet | US$2.382B (2024) | B2B firmographics, beneficial ownership (595M+ records) |
| 7 | Acxiom (IPG subsidiary) | Parent IPG: US$10.889B (2025) | Identity resolution, audience data, 3,000+ attributes per person |
The number that should stop you on Acxiom: the company maintains profiles on roughly 2.5 billion people globally, with 10,000+ attributes per person, and its dataset, combined with the rest of the IPG identity stack, reaches more than 99% of the U.S. adult population. Walking through any American city, almost every adult you pass is a row in an Acxiom table somewhere, attached to thousands of attributes they never told the company about.
There’s a structural detail about Acxiom’s product line that the Roberson case exposed and that applies industry-wide: brokers typically split their products into a risk and identity verification side that consumers can access and dispute, and a marketing and audience side that consumers cannot. The first side has to be at least partially auditable because it touches FCRA-regulated decisions; the second side does not, and so it isn’t. The 100-page report Roberson received was the audit; the marketing graph behind it is not something he, or anyone like him, has any legal right to inspect in full.
The technical moat here is not raw collection. Plenty of companies collect data. The moat is linkage at scale — tying a transient cookie ID to a stable device, the device to a household, the household to a credit-bureau record, the credit-bureau record to a workplace, the workplace to a beneficial owner. Once a broker can do that linkage reliably, the value of every new dataset they buy goes up, because they can attach it to a person who already exists in the graph. This is why brokers buy from each other constantly. It is a circular marketplace whose purpose is to keep patching holes in the graph.
Cotality (formerly CoreLogic) sits underneath the property layer of the American economy — it pulls from 22,000+ data sources and claims real-time signal coverage on roughly 99.9% of U.S. properties, which is what lets lenders, insurers, and downstream brokers anchor a person to a physical address with confidence. LiveRamp sells the connective tissue: its RampID identity-resolution product and clean-room infrastructure are what most of the others use to actually match a hashed email to a device to a household across vendor boundaries. Neither company looks like Acxiom from the outside, but the rest of the stack quietly depends on both.
LexisNexis Risk Solutions is a useful illustration of the monetization side. Roughly 39% of the segment’s revenue comes from steady enterprise subscriptions; about 61% is transactional — fees charged every time an agency or corporation looks somebody up. The look-up is the product. The graph is the inventory.
The Northern Network: Canada’s Quieter Version
The Canadian market is smaller, more concentrated, and considerably less transparent. The Big Three credit bureaus operate here too — Equifax disclosed roughly US$271M in Canada-specific revenue in 2025 — but the more distinctive Canadian pattern is the telco-as-broker and weather-app-as-broker models that have grown alongside them.
Telus and the mobility-data question. Telus runs two related programs built on its wireless network data. The first, Data for Good, provides strongly de-identified, aggregated mobility data to academics and public-sector partners for research — work that, during the pandemic, included supporting NSERC-funded COVID research. The second, “Insights,” is the commercial arm that sells aggregated mobility analytics to enterprise customers. Telus’ own documentation says the data is de-identified and aggregated, that researchers operate under a controlled API and a program agreement that explicitly prohibits re-identification attempts, and that Telus mobility subscribers can opt out of having their de-identified location information used for third-party insights. Privacy advocates — notably OpenMedia — have pushed back on how meaningful the de-identification is in practice and on how visible the opt-out is to ordinary customers. Both things are true at once: the program has formal privacy controls, and those controls are doing real work on a dataset that, by its nature, describes where Canadians physically go.
Pelmorex and the weather app you don’t think of as surveillance. Pelmorex Corp. owns The Weather Network and MétéoMédia. Their apps are preinstalled on a meaningful share of Canadian phones, and they collect location data at a scale most users never internalize. A 2022 House of Commons ETHI committee investigation into mobility-data practices during COVID-19 revealed the chain: the Public Health Agency of Canada contracted with a company called BlueDot for geolocation data, and BlueDot in turn sourced that data from Pelmorex and from U.S. broker Veraset. Pelmorex’s position is that it discloses only aggregated mobility data to BlueDot, not individual records. The Office of the Privacy Commissioner examined PHAC’s handling of the data and reached findings on its own. What the chain shows is not a conspiracy — it is the ordinary plumbing of the broker economy operating exactly as designed: a weather app, a private aggregator, a federal customer, all moving location data through contracts most Canadians never knew existed.
Beyond Telus and Pelmorex, a tier of Canadian specialist platforms operates at scale, and their published numbers are not small. intelligentVIEW, marketed as Canada’s only integrated audience prospecting platform, advertises 30,000+ attributes and 94 prebuilt personas down to the six-digit postal code, with direct push integrations into Meta, Google, TikTok, StackAdapt, and DV360 — meaning a Canadian household profile assembled from Statistics Canada, the national census, and Numeris data can flow into a programmatic ad buy with no further consumer-facing step. Environics Analytics runs the PRIZM Premier segmentation system: 68 lifestyle types built from 60+ source databases and roughly 40,000 variables. Arima takes the opposite approach, generating a “Synthetic Society” of simulated Canadian consumers as a privacy-safer alternative to selling real records. Canada Post, sitting on top of the country’s mailing-address infrastructure, monetizes that registry with demographic overlays for direct mail and logistics. The Canadian picture starts to look the same shape as the American one — just more concentrated, less visible, and stitched together from different anchor institutions.
The Sourcing Architecture: Four Channels of Digital Exhaust
Every dossier the industry builds is assembled from a small number of repeatable channels. You don’t have to be paranoid to map them; the channels are openly advertised on broker product pages.
1. Public registry ingest. Automated scrapers pull from real estate deeds, property tax filings, voter registrations, marriage and divorce records, court filings, professional licensing rosters, and corporate registries. This is the foundational demographic layer. It is also the cheapest, because the source records are already public.
2. Commercial exhaust. Retailers, loyalty-program operators, credit card issuers, and subscription services license their transactional data — SKUs, timestamps, basket sizes, merchant categories — to brokers under data-sharing agreements. Brokers use it to infer brand affinity, household income, and “spending power” categories. The retailer gets a check; the broker gets a behavioral layer the retailer alone could never have stitched together.
3. Digital signal ingest. This is the most invasive channel and the one most people imagine when they hear “tracking.” Tracking pixels embedded in emails and web pages, mobile SDKs embedded in apps, and server-to-server postbacks from ad exchanges feed brokers a constant stream of device IDs, IP addresses, GPS coordinates, browser and device fingerprints, and behavioral events. The mobile SDK channel is especially powerful because mobile devices report stable IDs — the iOS IDFA or Android Advertising ID — that can be cross-referenced against earlier sessions years later.
4. Utility account logs. This one is underdiscussed. Water, gas, and electric utilities license billing records — names, service addresses, account-open dates, household size proxies — to specialist brokers who use the data to verify physical residency in a way no purely digital signal can match. If you ever wondered how a people-search site keeps confidently listing the address you actually live at even after you’ve stripped your digital footprint, this is usually the answer.
These four channels are not isolated. The broker’s job is to layer them. The same person shows up in a voter file (channel 1), a loyalty database (channel 2), a mobile-ad impression log (channel 3), and a utility billing dataset (channel 4). Each appearance is a different identifier — a name spelled three different ways, a hashed email, a Mobile Ad ID, an electric account number. Stitching those identifiers into a single record is the next step.
Identity Resolution: How the Stitching Actually Works
The technical term for the stitching is identity resolution, and it is the part of the industry the rest of the stack quietly depends on. Each broker has a branded version — Acxiom’s Real ID, TransUnion’s TruAudience, LiveRamp’s RampID, Epsilon’s CORE ID — but the underlying engineering pattern is consistent.
The system maintains a graph. Nodes are identifiers: hashed emails, mobile ad IDs, household addresses, phone numbers, device fingerprints, cookie IDs. Edges are co-occurrences: this hashed email was seen in the same login session as this device ID; this device ID was seen at this household address overnight, repeatedly, for three months; this household address appears in a utility billing record under this name. The graph is probabilistic, not deterministic. Every edge has a confidence score, and every cluster of nodes is collapsed into a persistent “person” or “household” key.
The output is device fingerprinting at scale: a stable identity derived from hundreds of individually weak signals, none of which on its own would identify you. That is the property that makes browser anti-tracking features less effective than they feel. You can clear your cookies. You cannot easily clear your IP-history, your device’s user-agent quirks, your installed-fonts list, your habitual login times, the addresses you sleep at, and the credit-bureau record sitting in the background to anchor the rest. The graph will recognize you again within hours, sometimes within minutes.
This is also why “opt-out” is structurally hard. When you ask a broker to delete your record, the broker can delete the row keyed to your name. The graph, though, was built from the underlying signal sources. The next quarterly ingest from a public records vendor, a utility partner, or a digital signal feed will reconstruct a record that looks an awful lot like yours, attached to a freshly minted person key.
The dossier is not a future risk. It already exists, for almost every adult in North America, and it was built without you.
Read on: Part 2 — The Surveillance Pipeline, the Breach Record, and the Regulatory Pushback and Part 3 — Privacy Practices: The Operational Stack That Actually Works.